
GPT-5.2 正式対応レビュー|GDP Value 74%が示す「実務で使えるAI」への転換点【検証】
〜GPT-5.2で何が“本当に”変わったのかを実務視点で整理〜

これまでの生成AIは、「文章がうまい」「検索ができる」「数学やコードが解ける」といった「能力単位」で評価されてきました。
しかし実際の日常の業務において、資料を読み → 判断し → 表やExcelにまとめ → 次のアクションにつなげるという“連続した業務”が求められることも。
今回リリースされたGPT-5.2は、その実務連続性を数値で示すことに踏み込みました。キーワードは 「GDP Value 74%」。
この記事では、この数字が何を意味し、どの業務で・どう使うと価値が出るのかを、競合モデル比較と業務設計の視点で解説します。
目次
- TL;DR(先に要点)
- 何が新しい?(アップデートの本質)
- 使い方:最短ハンズオン
- 長文コンテキストの飛躍的向上(分断・読み落としを防ぐ設計)
- どちらを使う?(公式機能 vs 代替/併用ツール)
- 実務ワークフローへの組み込み例
- まとめ
TL;DR(先に要点)
- GPT-5.2の本質は「文章力」ではなく実務完遂率新指標「GDP Value」で専門業務の74%が人間同等以上
- 長文理解(12.8万トークンで97%)が飛躍的に改善
- Gemini 3はマルチモーダル、GPT-5.2は業務処理特化
- まずは「読み・整理・判断」が絡む業務から導入するのが安全
何が新しい?(アップデートの本質)
GPT-5.2の立ち位置
今回の5.2のアップデートで特にOpenAIが強調したのは、「専門業務を任せられるか」という一点です。
その象徴が「 GDP Value」 という独自ベンチマーク。
GDP Valueとは
AIが仕事としてどれだけ稼げるかを測るための、OpenAI社独自の実務価値ベンチマーク。
44業種、約1300件の実務タスクでPDF読解やExcel分析、スケジュール理解など、人間評価者と比較し「同等以上か」を判定
結果:
GPT-5 → 39%
GPT-5.2 → 70%
GPT-5.2 pro → 74%
これは「便利」ではなく「仕事として成立するのか」の割合です。
使い方:ハンズオン
GPT-5.2モデルでシンキングモードを有効化し以下のプロンプトを入力
プロンプト:(公式サイトより引用)
人員計画モデルを作成してください。ヘッドカウント、採用計画、離職率、予算への影響を含め、エンジニアリング、マーケティング、法務、営業部門を対象とします。
GPT‑5.2 Thinking では、GPT-5.1 Thinkingと比較し、スプレッドシートやスライドの書式設定が向上していることが比較で確認できます。
長文コンテキストの飛躍的向上(分断・読み落としを防ぐ設計)
GPT-5.2 Thinkingの最大の進化点のひとつが、長文コンテキスト推論能力の飛躍的向上です。
OpenAIが実施している長文推論ベンチマーク「MRCRv2」において、GPT-5.2 Thinkingは、長い文書に分散した情報を正確に統合する能力でトップレベルの性能を示しました。
特に、数十万トークン規模の情報を扱う「4-needle MRCR(最大256kトークン)」では、
ほぼ100%の精度を達成した初のモデルとされています。
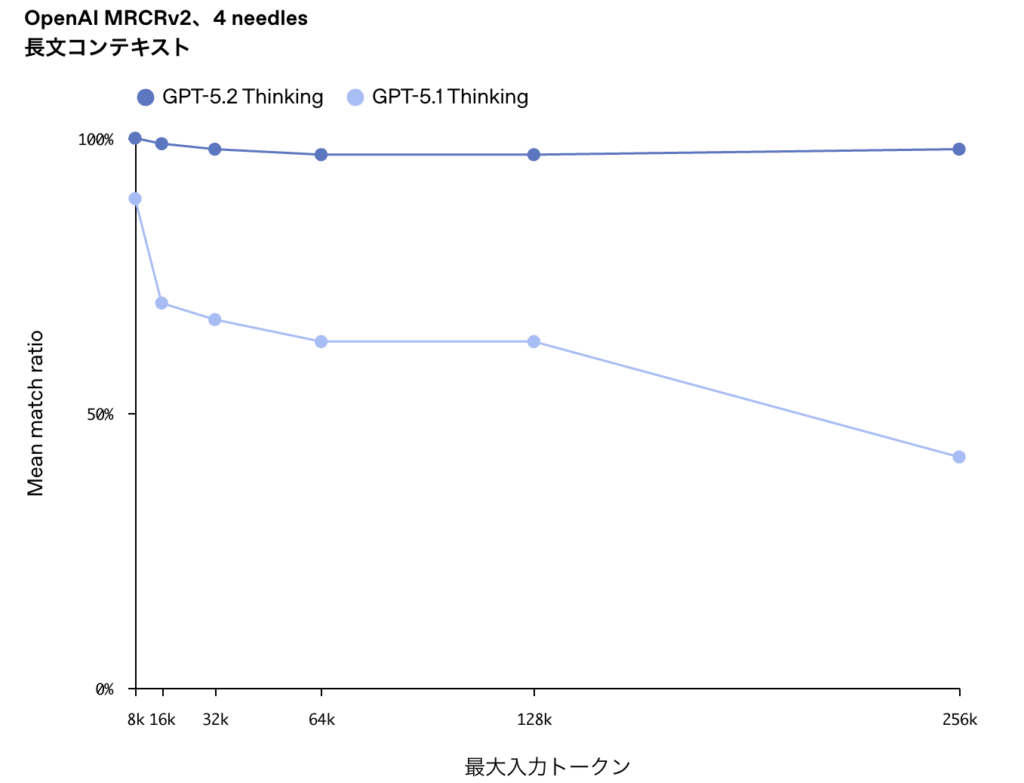
何が変わったのか(GPT-5.1との違い)
GPT-5.1 Thinkingでは、
- 長文は読めるが、後半で文脈が崩れる
- 複数箇所に散らばった条件を取りこぼす
- 結論は合っているが、根拠が一部ズレる
といった課題がありました。
GPT-5.2 Thinkingでは、
- 数十万トークンに及ぶ情報を前提として保持
- 文書全体を横断した整合的な判断
- 「どこに何が書いてあったか」を踏まえた推論
が安定して行えるようになっています。
実務で特に効果が高いユースケース
GPT-5.2は、以下のような長文・多資料前提の業務で真価を発揮します。
- 契約書・規約・約款の全文レビュー
- 調査レポート・研究論文の横断比較
- 会議書き起こし+資料を含む意思決定整理
- 複数ファイルにまたがるプロジェクト資料の統合
- 長期案件における経緯・前提条件の把握
数十万トークン規模でも、
一貫性と精度を保ったまま分析・要約・判断が可能です。
どちらを使う?(各社の性能比較)
各社のモデル比較
| 観点 | GPT-5.2 | Gemini 3 | Claude |
|---|---|---|---|
| 実務完遂力 | ◎ | ○ | ○ |
| マルチモーダル | △ | ◎ | △ |
| コーディング | ○ | ◎ | ◎ |
| 長文理解 | ◎ | ○ | ○ |
- 業務処理・判断 → GPT-5.2
- 画像・動画中心 → Gemini 3
- 実装・コード重視 → Claude・Gemini3
推論スピードと作業リズム
| 観点 | GPT-5.2 Thinking | Gemini 3 |
|---|---|---|
| 推論スピード | ◎ 思考ありでも速い | ○ やや待ち時間あり |
| 試行回数 | 多く回せる | コスト・時間で制限 |
| 業務リズム | 止まりにくい | 一時停止が発生 |
GPT-5.2 Thinkingは、深い推論を伴うタスクでもアウトプットが非常に速く、Gemini 3と比較しても待ち時間が短い傾向が見られます。そのため、
- 判断待ちで作業が止まりにくい
- 試行回数を増やしやすい
- 連続処理に向いている
といった点で、業務のテンポを重視するケースではGPT-5.2が有利です。
実務ワークフローへの組み込み例
- 入力:資料・データをまとめて投入
- 探索:要点抽出・論点整理
- 再編集:提案書・判断メモに変換
- 共有:テンプレとしてチーム展開
属人作業を再利用可能な標準プロセスに変えることが重要です。
まとめ
GPT-5.2は、単なる性能向上モデルというよりも、「実務で使われること」を前提に再設計されたアップデートだと言えます。
公式発表でも強調されている通り、長文コンテキスト推論や複雑なタスク処理において、従来モデル(GPT-5.1)を大きく上回る精度を示しています。
特に注目すべきは、長文・多情報統合能力の向上です。
数十万トークン規模の文書を前提にしても、一貫性を保った推論や判断が可能になったことで、契約書、レポート、研究資料、複数ファイルにまたがるプロジェクトといった、実務で避けられない長文ドキュメント処理が現実的な選択肢になりました。
また今回のGPT-5.2では、長文処理だけでなく、コーディングや理数学分野における精度向上も公式に示されています。
段階的な思考を必要とする問題や、仕様理解を前提としたコード生成・修正において、より安定した推論と結果が得られる点は、開発・分析業務においても重要な進化です。
さらに、ハルシネーション(誤情報)の抑制や安全性の改善も進んでおり、
「試験的に使うAI」から「業務プロセスに組み込むAI」へと一段階進んだ位置づけが明確になっています。
総じてGPT-5.2は、
- 長文・多資料を前提とした分析
- 複雑な業務フローへの対応
- コーディング・理数学タスクの安定性
- 実務利用を想定した信頼性
をバランスよく引き上げたモデルです。
まずは一部業務から小さく導入し、精度・スピード・再現性を確認しながら標準化していくことで、GPT-5.2の価値を最大限に引き出すことができるでしょう。
弊社では、生成AI導入初期フェーズのガイドライン策定や運用戦略、組織的業務効率化のAIソリューションパートナーとしてAI活用支援を行っております。
まずはじめに何をすればいいのか、業務にしっかり組み込んで運用するにはどうしたらいいか?などお悩みの際にはお気軽にお問い合わせください。
\お気軽にお問い合わせください。初回相談は無料で承っております。/

